
A. Disturbing Distribution
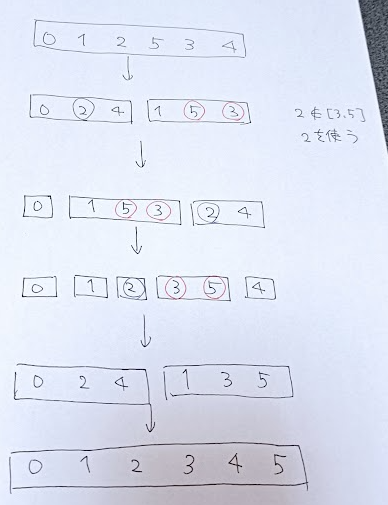
$2$ 以上の要素を $2$ 回使う方法は,バラしても損しません.
結局,$2$ 以上の要素は単体で使うと固定した上で,$1$ をなるべくそれらに混ぜようとするのが最適です.
B. Everything Everywhere
最大値を $a$,最小値を $b$ として最大公約数を $g$ とします.$a=b$ は除外されます.
$a,b$ は $g$ の倍数で差が $g$ なので,これらの間に他の $g$ の倍数はありません.
よって,good subarray では値の種類が $a,b$ の $2$ 個だけです.順列であることから長さ $2$ のものを調べればよいです.
D. Reserved Reversals
難しい.未証明.
苦戦した挙句,No となる十分条件を適当に探すと通りました.
偶数の $x,y$ ($x>y$)を左・右順にとったときに,これらの位置関係を変えたいですが,これらの位置関係を変えるにはこれら両方の数を含む区間による reverse が必須です.結局,奇数 $z$ であって $x$ 以上または $y$ 以下のものの存在が必要です.
偶奇を逆にした必要条件も処理します.
証明成功.
上の必要条件を仮定します.
まず,隣接する奇数と偶数はスワップ可能です.したがって,「奇数同士の順序」「偶数同士の順序」を保った変形は可能です.
まず,偶数を左側,奇数を右側に分離しましょう.そのあと,奇数同士の転倒対に対する隣接スワップを行えることをチェックします.
奇数の隣接転倒 $a>b$ があったとき,必要条件から偶数 $c$ であって $c\notin [a,b]$ をとってきて,偶数同士,奇数同士の位置関係を保ったまま $\ldots,a,b,c,\ldots$ と並べます.あとはこの $3$ 項に操作すればよいです.
E. Mental Monumental (Hard Version)
やや実装に苦戦.おおよそ次の手順です.
- $k=0$ で初期化.
- 各 $i$ について,次を行う:$mex > k$ にできるか?という判定問題を解く.true である間 $k$ をインクリメントし続ける.
答は単調なので,これで「判定問題を解く」回数が $O(N)$ 回になります.
あとは判定方法です.$c$ の変更先は,$c$ 自身または $\lfloor (c-1)/2\rfloor$ 以下の何かです.次を仮定できます.
- $c\leq k$ かつ最初の出現であるような,$c$ は変更しない.
結局,固定値で使うものは決まっていて,他のもの,「$x$ 以下なら何でも使える」というような条件になります.
おおよそ,$x=\ldots,1,0$ の順に次のアルゴリズムを実行します.
- 「$x$ 以下なら使える」というものの個数を $cnt$ に加える
- 固定値で $x$ として使うというものの個数を $cnt$ に加える
- $x\leq k$ ならば,$cnt$ から $1$ を引く(ひとつ割り当てる)
- この過程で $cnt<0$ に到達することがあれば判定問題は false.
ある区間での過程において,$cnt=0$ からスタートした場合の,最終的な $cnt$ および道中での $cnt$ の min を持つというセグメント木でできます.
$k$ のインクリメントに応じて,$c$ を固定値として使うかの変更が入ることがあるので,$O(1)$ 箇所のセグ木の値を書きかえたりします.
F. Inversion Invasion
まず,並べ替えの方法は数えられます.$a_i=x$ となるものに $\varphi(n/x)$ 個の値を入れた後,残りをランダム順列という容量です.
転倒数は,転倒数期待値を考えます.期待値を,$(i,j)$ ごとに数えることにします.
まず,$p_k=n$ とする $k$ を固定して考えます.すると,$i\neq k, j\neq k$ ならば,$(i,j)$ の転倒確率は $1/2$ であることが分かります.これは,$a_i=0$ の場合なども含めてそうなります.$x$ を書き込む方法と $n-x$ を書き込む方法を対応させて平均化する感じで.
結局,あとは,$p_k=n$ とする $k$ をとって,$(k,i)$ の形の転倒を考えたときの値を足します.$a_i=n$ となる $i$ が $0$ 個か $1$ 個かで場合分けをします.$0$ 個の場合には,$a_i=0$ となっているような $i$ の個数や和などを管理しておけばよいということになります.
ちゃんとやれば $O(N)$ 時間のはず.
G. Stop Spot
まず,$p_i$ を使わない回文を数えておきます.Manacher, palindromic tree など.
$p_i$ を使う回文はどうなるかというと,まず $p_i$ が順列であることから,回文中心は $n$ までの部分にきます.
として,「$p$ の prefix と何かの lcp の加点」という要領でスコアが計算されます.
例えば $A=[2,3,1,1,1,1]$ だとすると,
- 回文の中心が $6$:$[1,1,1,1,3,2]$ との lcp だけ加点.
- 回文の中心が $5$:$[1,1,3,2]$ との lcp だけ加点.
- 回文の中心が $4$:$[3,2]$ との lcp だけ加点.
となります.
そこで,reverse(A) の suffix array を用意して,加点対象となる suffix も適切に求めておきます.
あとは何をやるかというと,suffix tree 上を dfs しながら答を求めるという雰囲気のことをします.
上の例だと,
- $p_1=1$ と決める.subarray の個数が $4\to 6$ となるものが $2!$ 通りある.$p_2$ を決めるフェーズに移行.
- $p_2$ を決めようとすると,上手くいくものがないので,戻る.
- $p_1=3$ と決める.subarray の個数が $4\to 5$ となるものが $2!$ 通りある.$p_2$ を決めるフェーズに移行.
- $p_2=2$ と決める.subarray の個数が $5\to 6$ となるものが $1!$ 通りある.$p_3$ を決めるフェーズに移行.
みたいな雰囲気です.
suffix tree の探索は,このように「$1$ 文字ずつ見る」方法では,通常計算量がやばくなりがちです.
今回は $1$ 文字ずつ見ても,探索回数 $O(N\log N)$ になるはずです.
問題になるのは,$A$ の palindrome suffix がたくさんあるときです.
この場合,palindrome suffix は $O(\log N)$ 個の周期的なものに分けられます.palindrome suffix が border であることと,border の一般論より($M<N$ の border があると周期 $p=N-M$ があって,しばらくは $M-p,M-2p,\ldots$ などが border になっていく).
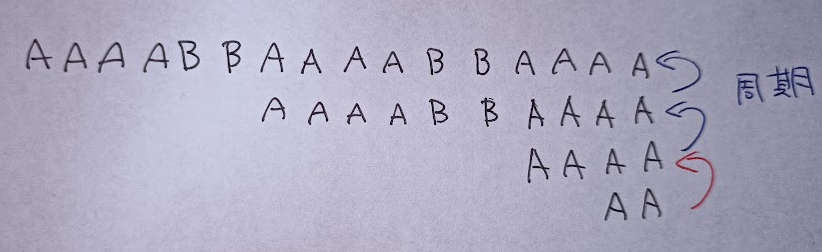
そして,$p$ を順列にしなくてはいけないことから,周期的な suffix の列について $O(1)$ 個を除いて同時に同じ禁止条件に引っかかってります.したがって,dfs は結局 $O(\log N)$ 個の suffix に沿って進むため,探索回数 $O(N\log N)$ になります(私の実装は $O(N\log ^2 N)$ になっています).
いやもっと簡単だった.偶数長回文 suffix $X, Y$ ($|X|>|Y|$)があるとき,$Y$ に追加できる順列の長さは $|X|-|Y|$ 未満.なぜならばここの部分にはすべての値が偶数回登場するからここまで行くと順列になれない.すべての回文に対してこの評価を行えば,合計文字数 $N$ 以下になっている.
結局合計文字数 $N$ 以下の trie で解けるということになる.
