
ABCコンテスト 過去問感想 → ■
ARCコンテスト 過去問(~057, A・B難易度)感想 → ■
ARCコンテスト 過去問(~057, C難易度)感想 → ■
全体感想
ここからE問題表記です。何とか埋まりました。面白かったー(^^)
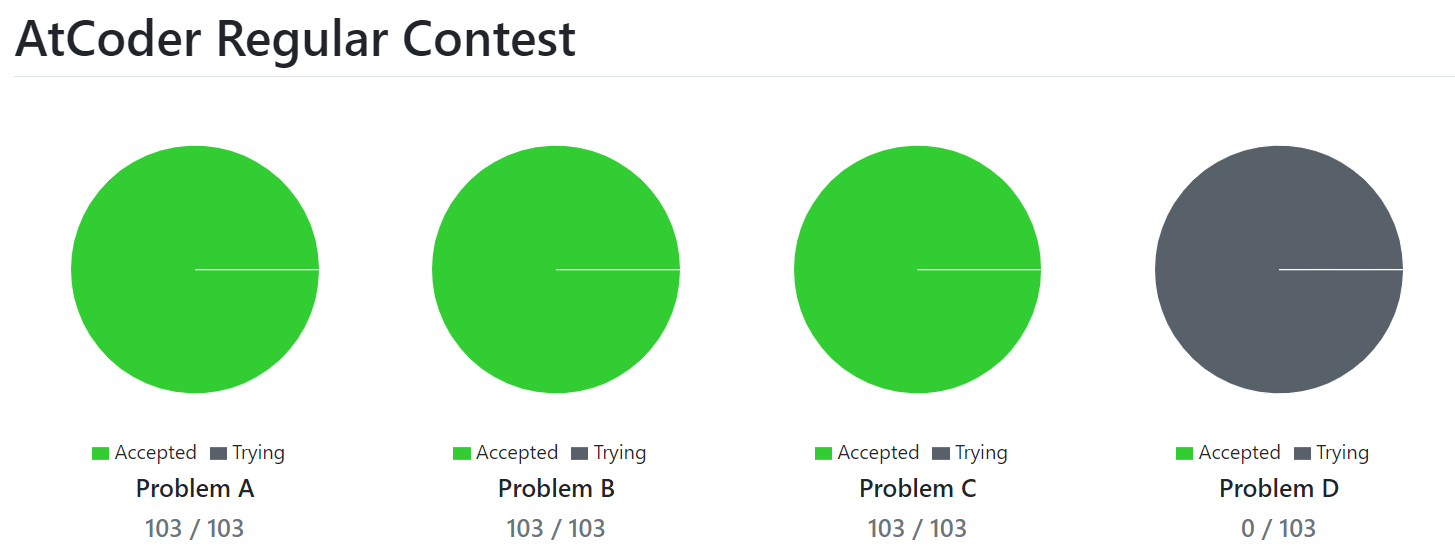
難易度は、~057のC問題を引き継いでいる印象があります。
ただ、こちらの方が易問が少なくて密度が濃いという印象でした。
難問リスト
個人的に数時間単位でかかったものなど。考察が難しかったもの、実装が難しかったものなどごちゃまぜ。一応雑にリストアップしておきます。個人差もあるかと思います。
・ARC065 へんなコンパス
・ARC068 Snuke Line
・ARC070 NarrowRectangles
・ARC080 Young Maids
・ARC085 MUL
・ARC086 Summggling Marbles
・ARC087 Prefix-free Game
・ARC089 GraphXY
・ARC093 Bichrome Spanning Tree
・ARC096 Everything on It
・ARC098 Range Minimum Queries
・ARC101 Ribbons on Tree
個別感想
問題文:■ 自分の提出:■
べき乗和を畳み込んでいく感じの計算になる。
FFTによる畳み込みの計算誤差対策。int8 -> int16 -> int32 と積んで、FFTを合計9回呼んでいる。実装の頭の使わなさがお手軽。 pic.twitter.com/PapEyL2nBO
— maspy (@maspy_stars) July 6, 2019
このFFTを使った。
問題文:■ 自分の提出:■
難しかった。確かに、座標変換(回転拡大)して一様距離に書き換える方が考えやすかった。
半径は一定で、適当な連結成分上の辺の個数を数える問題だと思える。偏ったデータで答が$O(N^2)$ となる場合がある($2$ 本の平行線上に密に並べる)ため、 $1$ 本ずつ見ていては条件を満たす線分だけに注目できたとしてもアウト。何かしらでまとめてやりくりする必要がある。
ということに注目して考えていると、まずは各頂点に対して距離 $R$ (半径)の点の個数を取得する方法が分かる。でも結局これらを全部連結にしていこうとすると1つ1つ見なきゃいけなくて、上手くいかない。
最終的には、2つの課題を切り離して考えることが有益だった。連結成分を拡大するときには、未注目の距離 $R$ を全て順番に見ていく。連結成分の拡大は $O(N)$ 回しか起こらないのでこれでよい。一方、辺の数を数えるときには1つ1つ見ていくのではなく、全部一括で個数だけ拾うようにする。
問題文:■ 自分の提出:■
難問。何か分かりやすい解法があるのではないかとしばらく考えるも、特に簡単にならない。
下から順に「関数ごと更新していく」感じの漸化式を考える。$n$ 段目の長方形の座標ごとに、$n$ 段目までの最小値を持つ関数を $f_n$ とすると、$f_{n+1}$ は
\[ f_{n+1}(x) = \lvert x-a\rvert + \min_{-b\leq t\leq c} f_n(x+t) \] のような式で書けることが分かる。このことから、$f_n$ が常に局所 $1$ 次関数であること、傾きは至るところ整数で、下に凸になることなど、形状がおおよそ定まっていく。
そもそも「関数全体を持って、更新していく」とやるのは無理があり、データで扱える形(有限個の整数や実数の組)で関数を表す必要がある。これは、ここまで関数の形が限定されたのでできる。傾きの変化点を持つことにした。あとはまぁ一直線に、といってもそれなりにテクい。平行移動して $\min$ をとるところで、傾きの変化点が一斉に平行移動される。これを全ての値に定数を加えていては計算量が大きすぎる。ただ、これは「真の値はこの値からいくつ足されたものですよ」という情報を1つ余分に持つことで対応できる。
実装は、ABC 127-F と似た雰囲気であった。これは当時のコンテストで、場合分けの多い複雑なコードを書いてしまったせいで、バグが取り切れず解ききれなかった問題。他の方のコードを参考にしてミスしにくい実装を考えながらしっかり反省した問題だったので、その経験が活きて、本問題では実装は苦戦しなかった。
push_L = lambda x: heappush(S_lower, -x)
push_R = lambda x: heappush(S_upper, x)
pop_L = lambda: -heappop(S_lower)
pop_R = lambda: heappop(S_upper)この辺は、初の試みだが、コードが書きやすくなって良かった。heapqに格納して最大値を取り出せるようにするやつ。他には、傾きが $-1$ から $1$ に変化するところは、同じ点で $2$ 回傾きが変わると見なして統一的な実装をするなど心がけた。
問題文:■ 自分の提出:■
お気に入りの値を $x$ とすると、各課題$a_i\mapsto a_{i+1}$に対して必要回数 $f(x)$ が出来る。これを全ての課題に対して足していけばよい。$f(x)$ そのものを更新するのはしんどい。傾きが$0$, $1$ の $1$ 次関数をつないだ形。よって、差分 $\Delta f(x) = f(x) – f(x-1)$ を持つことにする。これは局所定数関数。さらに $\Delta \Delta f(x) = \Delta f(x) – \Delta f(x-1)$ を考える。これはほとんど至るところ $0$ なので更新が容易である。$\Delta \Delta f$ の課題に対して集めて、そこから $f$ を復元すればよい。
問題文:■ 自分の提出:■
これは難しかった。というか、最終的な解答はかなり自然なことをやっているだけなのだが、ほんの少し実装法を変えただけなのに計算量が大丈夫になるところが分かりにくい。
根から順に、各時刻にコインが $0$ 枚、$1$ 枚となるような確率を持つのは自然。複数の根から合流するところは、$0$枚、$1$枚、$2$枚以上と分けてマージしていけばよい(ここもまぁまぁ悩んだ)。最終到達時刻ごとに計算すると、$O(N^2)$ になってしまう。全時刻のデータを同時に持って、共通の深さ分だけマージする形にしてあげる。各頂点に最初にあったコインはマージ元側になるのが1回以下になるので、$O(N)$ になる。
問題文:■ 自分の提出:■
prefixの関係を図示すると、完全二分木ができる。これに禁止ルールを追加していくと、完全二分木に分解されることが分かる。よって、それらのgrundy数をxorすればよい。
完全二分木のgrundy数は、最初にどれをとるかで場合分けして、計算できる。が、深さ $N$ の場合を計算するのに、これまでの数表を持った上で $O(N)$ の計算が必要。問題は $10^{18}$ までを要求しているので、もっと簡単に計算できないとまずい。
ゲームのgrundy数は、理論的な導出というよりも、しばしば小さい数で実験して規則を見つけるという方法が使われる(見つけられれば証明は易しい)。今回も、小さい場合を計算させてみて、規則を予想・証明する形をとった。
問題文:■ 自分の提出:■
各経路の距離が、$X$, $Y$ の1次式になる。1次式の集合があり、各 $x,y$ に対する最小値が与えられていることになる。
最小値に対してどのような $1$ 次式を追加していけばよいのかを考えたが、全然進展しない。まず、$1$次式は作りすぎてもよいことに気づく。つまり、任意の $(a,b)$ に対して $ax+by+c$ という式を1つずつ作ることにする。$c$ を十分大きくすれば、$1$次式を作らなかった場合と同一視できる。
この着想が良かったのか、各 $(a,b)$ に対してどのような $c$ を持てるかという視点を得る。これは簡単だ。与えられた最小値群を下回らない範囲でなるべく小さい $c$ を選べば良い。ここまでできれば簡単で、$ax+by+c$ を下側に矛盾しない範囲で最善の作り方ですべて作って、条件を満たすかの検証をすれば良かった。
いろんな $a,b,x,y$ に対する計算をまとめていたら、numpyの4次元arrayになった。
最小全域木の重みが$x$であれば、$X> x$なら最小全域木は同色でなければいけない。というのが最初の気づき。ここから「ある最小全域木に含まれる辺は全て同色」と言いたいが、例えば最小全域木が $A,B$ の2つしかなくて、これらが共通の辺を持たない場合、「それぞれ同色」までしか言えない。しかしそういうことはなさそう。同様に、「ある重み$X$未満の全域木に含まれる辺が同色」も証明できそう。
証明は解説PDFにもあまり明快に書かれていないように思う。結局次が成り立つ:
【命題】 $G$ を辺に重みがついたグラフ、$T$ を最小全域木のひとつ、$e$ を $T$ に含まれない辺とする。このとき、$G$ の全域木で $e$ を含むもののうち重み最小のものは、$T$ に $e$ を加えて、できる閉路から $1$ 辺除くことで得られる。
これは、例えば最小全域木がクラスカル法で計算できることから分かる。「$e$ を必ず含む」という条件下での最小全域木を求めることは、$e$ を縮約したグラフ上での最小全域木を求めることと等価。すると、クラスカル法のアルゴリズムが、$e$ の端点の連結成分をつなぐ部分を除いて同等に再現される。
この構成より、最初に最小全域木 $T$ をひとつとり固定すると、$T$ は単色。
ある辺 $e$ を含む全域木の最小コストが $X$ 未満であれば、その全域木は $T$ と辺を共有するものにとれるので、$e$ も $T$ と同色であることが分かる。結局 $e$ を含む全域木の最小コストが $X$ より小さい・等しい・大きいのグループごとに、単色、逆色があればよい、自由、などという単純な条件になり解けた。
「$T$ に $e$ を加えたときにできる閉路上の1辺」の長さを計算する必要があるが、ここはLCAの計算時に辺の長さの最大値も持たせればよい。
bitwise_orは、集合の和集合に対応する。$i\cup j \subset k$ となる $(i,j)$ に対する計算をする。これは$i\subset k$ かつ $j\subset k$ と同値なので考えやすい条件。$A=\{a_1,a_2,\ldots,a_n\}$ の部分集合は、ある $i$ に対して$A\setminus \{a_i\}$ の部分集合であることと同値なので、より小さい集合の場合の $n$ 個の計算から $A$ の場合が計算できて、計算量は $O(N2^N)$。
同じ数を2度使わないようにしないといけないところで最後にはまる。ここは、上位2件を持つことで解決。
通行止めする辺集合を決めると、各連結成分上で自由にペアを作る問題になるので包除の原理が使えそう。これまでいくつの反例を決め打ったか(偶数・奇数)、および、次に反例集合を広げる更新のために自由に使える部分の連結成分を持つ必要がある。
これは実装中に気づいたことで、反例の偶数個から奇数個を引いた差分だけ持って更新していく形で上手くいった。連結成分も辺の個数とか頂点の個数なのかとかで混乱しやすく、無限にバグを出した。
def dp_merge(data1,data2):
N1 = len(data1) - 1
N2 = len(data2) - 1
if N1 > N2:
N1,N2 = N2,N1
data1,data2 = data2,data1
data = np.zeros(N1+N2, dtype = np.int64)
for n in range(1,N1+1):
data[n:n+N2] += data1[n] * data2[1:] % MOD
data %= MOD
return dataここの処理で、データ長によって番号を入れ替えています。ここは2次元配列を1次元分高速化するようなことをやっているのですが、細かい枝をマージするときに、「長さ $N$ の配列と長さ $2$ の配列」というようなケースが多発していて、長さを入れ替えないと、長さ $N$ をpythonループ、長さ $2$ だけnumpyという感じになってTLEしていました。やってることは大体畳み込みで、np.convolveを使うと桁あふれしちゃうので処理を分解しています。
